dbt Core Part 2 - Setting Up dbt on GitHub
In part 2 of the dbt core setup series, we will review the setup process for each of the cloud data warehouses that we discussed on part 1. Before we can begin, there are some prerequisite items that need to be addressed:
- Complete Part 1 of the dbt core series
- Create a GitHub Account if you do not currently have one.
- Have a text editor available. We recommend Atom or Visual Studio Code.
dbt Set-Up
Fork dbt Setup from GitHub
- Fork this repository. The repository contains the beginning state of a dbt project.
- Clone the repository locally on your computer.
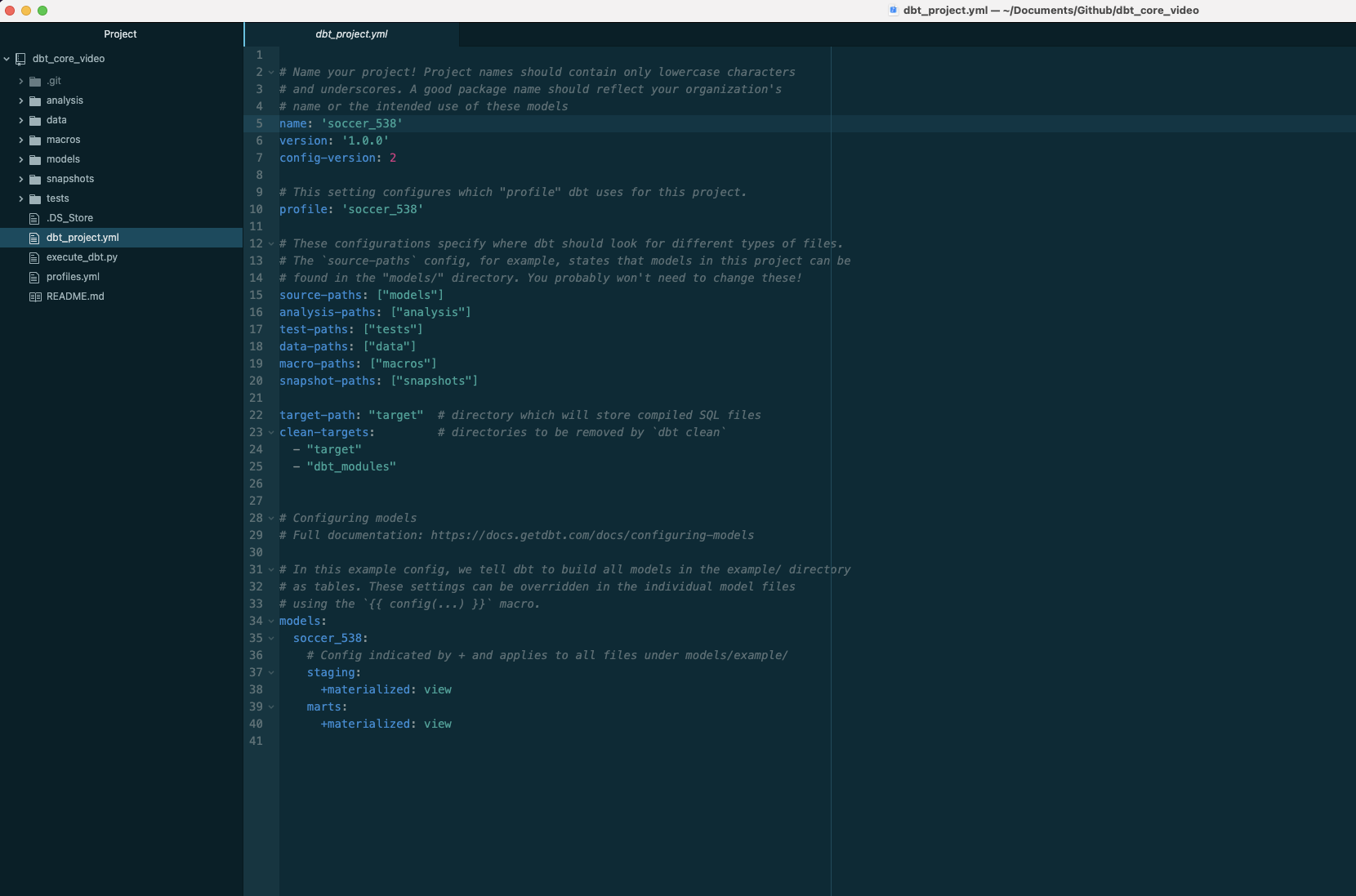
- Open
dbt_project.ymlin your text editor.
dbt Project File Setup
- Change the project name to
soccer_538. - Change the profile to
soccer_538. - Change model name to
soccer_538. - Under the soccer_538 model, add a
stagingandmartsfolder that are both materialized as views. - Save your changes.
dbt Profile Setup
- BigQuery
- Databricks
- Redshift
- Snowflake
- Open
profiles.ymland update the file to contain the following code:
soccer_538:
target: dev
outputs:
dev:
type: bigquery
method: service-account
project: dbt-demos # Replace this with your project id
dataset: dbt_shipyard # Replace this with dbt_your_name, e.g. dbt_bob
threads: 4
timeout_seconds: 300
location: US
priority: interactive
keyfile: "{{ env_var('BIGQUERY_KEYFILE') }}"
You'll note that the keyfile above is denoted as an environment variable. We will send that in as an environment variable inside of Platform to protect it from being seen.
- Create a new file in your root directory of your dbt project called
execute_dbt.py. - Paste this code block for the content of
execute_dbt.py:
import subprocess
import os
import json
bigquery_credentials = os.environ.get('BIGQUERY_CREDS')
directory_of_file = os.path.dirname(os.path.realpath(__file__))
dbt_command = os.environ.get('dbt_command', 'dbt run')
os.chdir(directory_of_file)
if not bigquery_credentials or not bigquery_credentials == 'None':
bigquery_credentials = json.loads(bigquery_credentials)
with open('bigquery_creds.json', 'w') as outfile:
json.dump(bigquery_credentials, outfile)
subprocess.run(['sh', '-c', dbt_command], check=True)
- Save your changes, make a commit, and push your changes to GitHub.
- Open
profiles.ymland update the file to contain the following code:
soccer_538:
target: dev
outputs:
dev:
type: snowflake
account: "{{ env_var('snowflake_trial_account') }}"
user: dbt_user
password: "{{ env_var('dbt_user_password') }}"
role: dbt_dev_role
database: dbt_hol_dev
warehouse: dbt_dev_wh
schema: soccer_538
threads: 200
- Create a new file in your root directory of your dbt project called
execute_dbt.py. - Paste this code block for the content of
execute_dbt.py:
import subprocess
import os
import json
dbt_command = os.environ.get('dbt_command', 'dbt run')
subprocess.run(['sh', '-c', dbt_command], check=True)
- Save your changes, make a commit, and push your changes to GitHub.
- Open
profiles.ymland update the file to the following contents, changing the schema to use your name and the correct http path:
soccer_538:
target: dev
outputs:
dev:
type: databricks
schema: dbt_jack_sparrow
host: "{{ env_var('databricks_host') }}"
http_path: /sql/your/http/path
token: "{{ env_var('databricks_token') }}"
- Create a new file in your root directory of your dbt project called
execute_dbt.py. - Paste this code block for the content of
execute_dbt.py:
import subprocess
import os
import json
dbt_command = os.environ.get('dbt_command', 'dbt run')
subprocess.run(['sh', '-c', dbt_command], check=True)
- Save your changes, make a commit, and push your changes to GitHub.
- Open
profiles.ymland update the file to contain the following code:
soccer_538:
target: dev
outputs:
dev:
type: redshift
host: hostname.region.redshift.amazonaws.com
user: "{{ env_var('redshift_username') }}"
password: "{{ env_var('redshift_password') }}"
port: 5439
dbname: analytics
schema: soccer
threads: 4
keepalives_idle: 240 # default 240 seconds
connect_timeout: 10 # default 10 seconds
ra3_node: true
- Create a new file in your root directory of your dbt project called
execute_dbt.py. - Paste this code block for the content of
execute_dbt.py:
import subprocess
import os
import json
dbt_command = os.environ.get('dbt_command', 'dbt run')
subprocess.run(['sh', '-c', dbt_command], check=True)
- Save your changes, make a commit, and push your changes to GitHub.
Now that we have our sample data and dbt processes setup, we need to write our example models for the dbt job to run.
dbt Models Setup
- Navigate into the models folder in your text editor. There should be a subfolder under models called
example. Delete that subfolder and create a new folder called538_football. - Create two subfolders inside
538_footballcalledstagingandmarts.

- Inside the staging folder, create a file called
stg_football_matches.sqlwith the following query:
- BigQuery
- Databricks
- Redshift
- Snowflake
SELECT *
FROM dbt-demos.538_football.stg_football_matches
SELECT *
FROM default.stg_football_matches
SELECT *
FROM soccer.stg_football_matches
SELECT *
FROM "DBT_HOL_DEV"."PUBLIC"."STG_FOOTBALL_MATCHES"
- Inside the staging folder, create a file called
stg_football_rankings.sqlwith the following query:
- BigQuery
- Databricks
- Redshift
- Snowflake
SELECT *
FROM `dbt-demos.538_football.stg_football_rankings`
SELECT *
FROM default.stg_football_rankings
SELECT *
FROM soccer.stg_football_rankings
SELECT *
FROM "DBT_HOL_DEV"."PUBLIC"."stg_football_rankings"
- In the staging folder, add a file called
schema.ymlwith the following code:
version: 2
models:
- name: stg_football_matches
description: Table from 538 that displays football matches and predictions about each match.
- name: stg_football_rankings
description: Table from 538 that displays a teams ranking worldwide
This is file is where you will be able to add tests later.
- In the marts folder, create a file called
mart_football_information.sqlwith the following query:
WITH
qryMatches AS (
SELECT *
FROM {{ ref('stg_football_matches') }}
WHERE league = 'Barclays Premier League'
),
qryRankings AS (
SELECT *
FROM {{ ref('stg_football_rankings') }}
WHERE league = 'Barclays Premier League'
),
qryFinal AS (
SELECT
qryMatches.season,
qryMatches.date,
qryMatches.league,
qryMatches.team1,
qryMatches.team2,
team_one.rank AS team1_rank,
team_two.rank AS team2_rank
FROM qryMatches
JOIN
qryRankings AS team_one ON
(qryMatches.team1 = team_one.name)
JOIN
qryRankings AS team_two ON
(qryMatches.team2 = team_two.name)
)
SELECT *
FROM qryFinal
- In the marts folder, add a file called
schema.ymlcontaining the following code.
version: 2
models:
- name: mart_football_information
description: Table that displays football matches along with each team's world ranking.
- Save the changes.
- Push a commit to GitHub
In this tutorial, we made changes using the main branch of our GitHub repository. This was done for simplicity sake and is not the best practice.
We are ready to move into Platform to run our process in the cloud.